|
FlowSieve
3.4.0
FlowSieve Coarse-Graining Documentation
|
|
FlowSieve
3.4.0
FlowSieve Coarse-Graining Documentation
|
A review of the computational methodologies (warning: math content).
Suppose that we are computing the filter at longitude 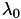 and latitude
and latitude  (at indices
(at indices 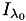 and
and 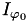 respectively) over length scale
respectively) over length scale 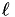 . Let
. Let 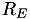 be the mean radius of the earth (in metres).
be the mean radius of the earth (in metres).
The integral is performed as a double for-loop, with the outer loop going through latitude and the inner loop going through longitude. In order to optimize the computation time, we would like to restrict the bounds on each of the for loops as much as possible.
This is implemented in Functions/get_lat_bounds.cpp
Suppose that we have uniform (spherical) grid spacing 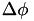 .
.
The spacing between latitude bands, in metres, is then 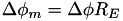 . The number of points that we'll include in either latitude side is then
. The number of points that we'll include in either latitude side is then
![\[\Delta\phi_N=\mathrm{ceil}\left( L^{pad} (\ell/2) / \Delta\phi_m\right).\]](form_15.png)
The outer loop in the integral is then from 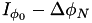 to
to  .
.
In this event, we simply use a binary search routine to search the (logical) interval ![$ [0, I_{\phi_0}-1 ] $](form_18.png) for the point whose distance from the reference point is nearest to, but not less than,
for the point whose distance from the reference point is nearest to, but not less than, 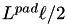 , and similarly for the (logical) interval
, and similarly for the (logical) interval ![$ [I_{\phi_0}+1, N_{\phi}-1 ] $](form_20.png)
Note that implicitly assumes a mesh grid (i.e. that the latitude grid is independent of longitude).
This is implemented in Functions/get_lon_bounds.cpp
The current implementation requires the longitudinal grid to be uniform.
Suppose that we have uniform (spherical) grid spacing 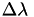 .
.
Next, at each latitude 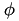 within that loop, the same process is applied to compute the bounds for the longitude loop, with the spacing between longitude band, in metres, given by
within that loop, the same process is applied to compute the bounds for the longitude loop, with the spacing between longitude band, in metres, given by  .
.
An equation identical to the one for 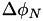 is then used to compute
is then used to compute 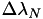 , which then gives the width of the integration region (in logical indexing) at that specific latitude.
, which then gives the width of the integration region (in logical indexing) at that specific latitude.
The scale factor 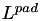 is a user-specified scaling to indicate how large of an integration region should be used. This is specified as KernPad in constants.hpp. That is, the numerical integration to compute the local coarse-grained value only includes points within a distance of
is a user-specified scaling to indicate how large of an integration region should be used. This is specified as KernPad in constants.hpp. That is, the numerical integration to compute the local coarse-grained value only includes points within a distance of  (in metres) from the target spatial point, so that
(in metres) from the target spatial point, so that  indicates that the integration area has a diameter of exactly
indicates that the integration area has a diameter of exactly 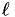 . This is implemented in the functions get_lon_bounds and get_lat_bounds, which determine the physical and logical integration bounds for a given point and filter scale.
. This is implemented in the functions get_lon_bounds and get_lat_bounds, which determine the physical and logical integration bounds for a given point and filter scale.
For details regarding the derivation of these quantities, please see the following publications.
Aluie, Hussein, Matthew Hecht, and Geoffrey K. Vallis. "Mapping the energy cascade in the North Atlantic Ocean: The coarse-graining approach." Journal of Physical Oceanography 48.2 (2018): 225-244: (https://doi.org/10.1175/JPO-D-17-0100.1)
![\[ \frac{\partial}{\partial t}\left( \frac{\rho_0}{2}\left| \overline{\vec{u}} \right|^2 \right) + \nabla\cdot J_{\mathrm{transport}} = -\Pi - \rho_0\nu\left| \nabla\overline{\vec{u}}\right|^2 + \overline{\rho}\vec{g}\cdot\overline{\vec{u}} +\rho_0\overline{F}_{\mathrm{forcing}}\cdot\overline{\vec{u}} \]](form_30.png)
![\[ \Pi = -\rho_0 S_{ij}\tau_{ij} = -\frac{\rho_0}{2}\left(\overline{u}_{i,j}+\overline{u}_{j,i}\right)\left(\overline{u_iu_j} - \overline{u_i}\cdot\overline{u_j}\right) \]](form_31.png)
Unit-wise,
![\[ \left[\rho_0 \right]=\frac{\mathrm{kg}}{\mathrm{m}^3}, \qquad \left[S_{ij} \right]= \frac{1}{\mathrm{s}} , \qquad \left[\tau_{ij} \right]= \frac{\mathrm{m}^2}{\mathrm{s}^2} , \qquad \left[ W \right] = \frac{\mathrm{kg}\cdot\mathrm{m}^2}{\mathrm{s}^3}, \qquad \Rightarrow \qquad \left[ \Pi\right] = \frac{\mathrm{W}}{\mathrm{m}^3} \]](form_32.png)
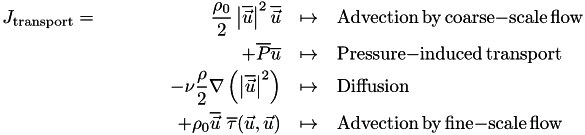
The following assume incompressibility:
![\[\nabla\cdot\overline{\vec{u}}=\overline{u}_{j,j}=0\]](form_34.png)
![\begin{eqnarray} \nabla\cdot\left(\frac{\rho_0}{2} \left| \overline{\vec{u}} \right|^2 \overline{\vec{u}}\right) &=& \frac{\rho_0}{2} [ (\overline{u}_i \overline{u}_i) \overline{u}_j ]_{,j} \\ &=& \frac{\rho_0}{2} (\overline{u}_i \overline{u}_i)_{,j} \overline{u}_j \\ &=& \rho_0 \overline{u}_i \overline{u}_{i,j} \overline{u}_j \end{eqnarray}](form_35.png)

Not implemented.
![\begin{eqnarray} \nabla\cdot\left( \rho_0 \overline{\vec{u}} \,\,\overline{\tau}(\vec{u}, \vec{u}) \right) &=& \rho_0 [ \overline{u}_i \tau_{ij} ]_{,j} \\ &=& \rho_0 \left( \overline{u}_{i,j} \left[ \overline{(u_iu_j)} - \overline{u}_i\,\overline{u}_j \right] + \overline{u}_i \left[ \overline{(u_iu_j)}_{,j} - \overline{u}_{i,j}\,\overline{u}_j \right] \right) \end{eqnarray}](form_37.png)
The spherical differentiation methods (spherical derivatives) use a land-avoiding stencil. Land avoiding is achieved by simply using a non-centred stencil when appropriate. This is done to avoid having to specify field values at land cells, as this may introduce artificially steep velocity gradients that would confound derivatives, particularly with pressure and density, where there's no clear extension to land.
The secondary differentation tools (Cartesian derivatives) simply apply the chain rule on the spherical differentiation methods.
![\begin{eqnarray} \arraycolsep=2.5pt\def\arraystretch{2.5} \left[ \begin{array}{c} {\displaystyle \frac{\partial}{\partial x} } \\ {\displaystyle \frac{\partial}{\partial y} } \\ {\displaystyle \frac{\partial}{\partial z} } \end{array} \right] &= \arraycolsep=2.5pt\def\arraystretch{2.5} \left[ \begin{array}{ccc} {\displaystyle \cos(\lambda)\cos(\phi) } & {\displaystyle - \frac{\sin(\lambda)}{r\cos(\phi)} } & {\displaystyle - \frac{\cos(\lambda)\sin(\phi)}{r} } \\ {\displaystyle \sin(\lambda)\cos(\phi) } & {\displaystyle \frac{\cos(\lambda)}{r\cos(\phi)} } & {\displaystyle - \frac{\sin(\lambda)\sin(\phi)}{r} }\\ {\displaystyle \sin(\phi) } & {\displaystyle 0 } & {\displaystyle \frac{\cos(\phi)}{r} } \end{array} \right] \arraycolsep=2.5pt\def\arraystretch{2.5} \left[ \begin{array}{c} {\displaystyle \frac{\partial}{\partial r} } \\ {\displaystyle \frac{\partial}{\partial \lambda} } \\ {\displaystyle \frac{\partial}{\partial \phi} } \end{array} \right] \end{eqnarray}](form_38.png)
In the case that we're restricing ourselves to a spherical shell, then 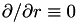 , so this reduced down to
, so this reduced down to
![\begin{eqnarray} \arraycolsep=2.5pt\def\arraystretch{2.5} \left[ \begin{array}{c} {\displaystyle \frac{\partial}{\partial x} } \\ {\displaystyle \frac{\partial}{\partial y} } \\ {\displaystyle \frac{\partial}{\partial z} } \end{array} \right] = \arraycolsep=2.5pt\def\arraystretch{2.5} \left[ \begin{array}{ccc} {\displaystyle - \frac{\sin(\lambda)}{r\cos(\phi)} } & {\displaystyle - \frac{\cos(\lambda)\sin(\phi)}{r} } \\ {\displaystyle \frac{\cos(\lambda)}{r\cos(\phi)} } & {\displaystyle - \frac{\sin(\lambda)\sin(\phi)}{r} }\\ {\displaystyle 0 } & {\displaystyle \frac{\cos(\phi)}{r} } \end{array} \right] \arraycolsep=2.5pt\def\arraystretch{2.5} \left[ \begin{array}{c} {\displaystyle \frac{\partial}{\partial \lambda} } \\ {\displaystyle \frac{\partial}{\partial \phi} } \end{array} \right] \end{eqnarray}](form_40.png)
This section outlines some of the parallelizations that are used. The coarse graining routine uses hybrid parallelization with OpenMPI (forks) and OpenMP (threads). This is done to minimize communication costs as much as possible.
The OpenMPI-based limit is:
The OpenMP-based limit is then:
If we then assign one OpenMPI processor to each physical compute node, this gives the over-all upper-bound on the number of processors that can be used as **(# Processors per Node) * Ntime * Ndepth**, assuming that the number of processors per node is constant.
Suppose you have a dataset with daily resolution, spanning ten years, but only at the surface.
Then Ntime = 365 * 10 = 3650 (ignoring leap years) and Ndepth = 1.
Further suppose that your computing environment has 24 processors per node.
You could then theoretically use up to 87,600 ( = 3650 * 1 * 24) processors.
Moreover, this is theoretically without encurring onerous communication costs, since the OpenMPI forks only need to communicate / synchronize during I/O, which only happens once per filter scale and once at the very beginning of the routine.
The time and depth loops are split and across processors with OpenMPI. At current, only time is actually split, but it is intended that depth will also be split across processors. Since the filtering routine only uses horizontal integrals, there is no need to communicate between different times and depths. This helps to avoid costly OpenMPI communication.
Horizontal (lat/lon) loops are NOT parallelized with OpenMPI. This is because there is a lot of communication required, especially when using large filtering scales or sharp-spectral kernels. This communication would be prohibitive.
The filter scales are also NOT parallelized with OpenMPI. This is because it would be difficult to load balance, particularly with non-sharp spectral kernels, where different filter scales would require very different amounts of time / work. Accounting for this would be non-trivial and, unless there were a large number of filter scales, not practical or efficient.
If parallelization across filter scales is truly desired, the simplest way would simply be to produce multiple executables and run them separately.
The horizontal (lat/lon) loops are threaded (openmp) in for loops. Both dynamic and guided scheduling routines are used to divide the work over the threads. These are used to give load balancing in light of the land/water distinctions. OpenMP uses shared memory, which avoids the need for (potentially very high) communication costs. There is a price to pay with scheduling, particularly since we can't use static scheduling (for load balancing reasons), but it's far less than would arise from OpenMPI.
The following functions occur within a time/depth for loop, and so do not use OpenMPI routines.
The following functions occur outside of time/depth for loops. However, the appropriate values for Ntime and Ndepth are passed through, so there's no need for further OpenMPI routines (outside of using the processor rank for print statements, of which there are none!).
This means that there's almost no modifications required, except for:
If you're running on a SLURM-managed cluster (such as the ComputeCanada clusters, Bluehive, etc), then you can submit using hybridized parallelization using the following submit script.
#!/bin/bash #SBATCH -p standard #SBATCH –output=sim-j.log #SBATCH –error=sim-j.err #SBATCH –time=02-00:00:00 # time (DD-HH:MM:SS) #SBATCH –ntasks=10 # number of OpenMPI processes #SBATCH –cpus-per-task=10 # number of OpenMP threads per OpenMPI process #SBATCH –mem-per-cpu=450M # memory per OpenMP thread #SBATCH –job-name="job-name-here"
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}
srun -n ${SLURM_NTASKS} ./coarse_grain.x
 1.8.13
1.8.13